The days of succeeding with email campaigns while sending a generic message are done. No one disagrees with this point. Everyone sees response rates dropping. The answer? On this point, people in the know also agree: The answer is segmenting your audience and...
My vision of big data, 11 prerequisites
Late yesterday I learned from Twitter that Whitney Houston died. 99% of the Whitney Houston Tweets were exactly, “RIP Whitney Houston.” Okay… but how did she move you? Do you remember a special dance with that one girl while she was singing? Was her voice so beautiful...
Deep Dive into hidden and protected pages – new sourcing technique “cache windowing”
I've tried this and it works every time. How long it will work, who knows. If you google a specific page and then search the page again... but this time using the last few words from the excerpt of the page results... you can use this technique to actually scroll...
Finding the right place for semantic search
Semantic search is a fantastic technology, if used correctly. I am not talking about users of semantic search technology, I am talking about the technology vendors that make it part of a system I was inspired to write this blog after reading Glen Cathey's (The...
Don’t search the Internet like a database
Having worked with many databases as well as having extensive experience in searching the Internet, I thought I'd share some thoughts on the differences between the two. When I observe people searching the Internet, there is a common mistake I see them making. Most...
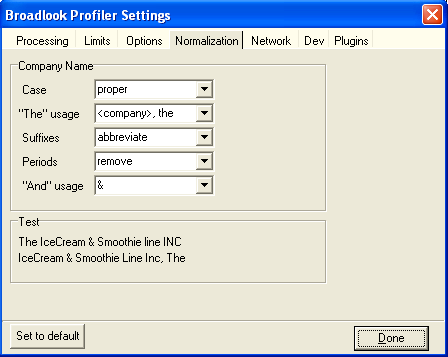
Avoiding a Data Nightmare – How data normalization can improve your bottom line
"Data normalization" is a phrase that leaves a blank stare on most peoples faces. Here is a secret: it is really simple. Here is the inside scoop: Technology people have a secret club, complete with handshake and everything. It's a club that we don't want...
One reason for CRM failure; The Nature of Contact Information
Most CRM implementations fail. This is a fact. Look it up. In my years in the industry, I've worked with many vendors on the consulting side to help reduce the possibility of CRM failure. While there is a whole host of reason that failure occurs, I have a very...
What is boolean? Is “Boolean Black belt” a good thing? What is Beyond Boolean?
There has been a recent rise of the term "Boolean blackbelt", while I am not familiar, specifically, with all the people stating to be a a boolean black belt, I wanted to add some perspective. "Boolean Blackbelt", may be a great marketing phrase, but it is the...

Keyword proximity and keyword extension engines
First engine is http://keywords.broadlook.com. The focus of this engine is the keywords and metatags within websites and build a list of (1) keyword extensions of your input.
Seamless voice recognition; recruiters get ready
I was recently speaking with my friend Ami Givertz and he asked me about technology that excites me. With this question, I realized that technology does not excite me; its the changes and possibilities that technology brings that excites me. In addition, I'm less...