I’ve been a fan of Cisco products for years. Today I had the most frustrating patronizing experience I’ve ever had with support.
Without diving into it, I had a new LinkSys (acquired by Cisco) router under warrantee and it was 30 minutes before they could find the registration information. I had to prove my contact information and serial number five times over five transfers.
Lesson of what happens when a big company acquires are small one. Service usually suffers. Not really worth my time to go into detail, however, I prefer working with small companies that have better service. Nuff said. This is a reminder to myself.
“I just called someone who’s been dead for a year”
If you’ve heard any of the above comments or something similar; you have a CRM problem. Are their solutions to these problems? Yes, however; today I will give you a deeper understanding of WHY the problem occurs. Many good vendors exist to solve the problems listed above. I want to arm you with a deeper insight, the WHY.
If you understand the WHY, you will be able to:
Have a deeper understanding to the nature of the problem
Remove unrealistic expectations (solve the problem, don’t chase a rainbow)
Define best practices to minimize bad data
Be informed when choosing a vendor (flashy interface does not solve THE PROBLEM)
Understand how your CRM decisions effect CRM data
Help you be an advocate for change management within your organization
Make you a more informed client (some vendors will like this, others will not)
So what is the WHY?
Short answer:
Contact data decays
If you have a short attention span, if you are brilliant, or have limited reading time, we are done here. That’s all you need and you know what I am going to say in the long answer. Thanks for reading.
Long answer:
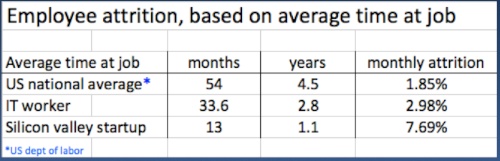
First, let’s establish a baseline from the US Department of Labor.
The national average tenure across all jobs in the US is 54 months. That breaks down to 1.85% per month of job attrition. For high-demand IT workers the tenure is shorter with 3% monthly job attrition rate. The rate for Silicon Valley start-ups is almost ridiculous with the average tenure being just over a year.*
*Not from DOL. garnered from several Venture Capital blogs…take it as an extreme example.
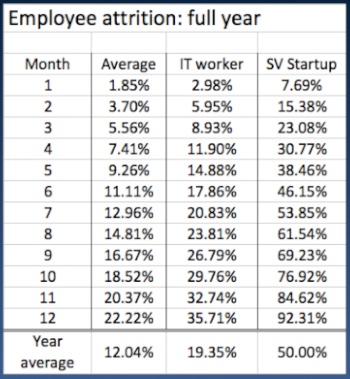
A full year of data decay – base factors
A month at a glance does not show the full picture when factored across an entire year. Look at the picture across a year’s time.
When reviewing an entire year, data will decay at about 12%. However, that does not take into account many additional factors including: (more…)
SIC codes are dinosaurs, they have not been updated since 1987. NAICS codes were updated in 2012, but they are still outdated.
No surprise when you think that these codes are kept updated by the government. Important new technologies are not represented by the SIC and NAICS codes.
What this means is that we must leave the SIC and NAICS codes behind if we are looking to have a clean, updated and current CRM system. What is the solution?
First, ask yourself, where is the best description of what a company does? Simple, the company’s own self-description is the best qualified. So imagine if you could have, live inside your CRM, all the keywords that accurately describe what each of your clients and prospects actually do today.
This technology already exists and it is called Market Mapper from Broadlook.
Market Mapper builds lists of companies, based on how a company self-describes itself. In addition, Market Mapper can be used to segment an existing list of companies.
Here is a live IceBreaker Video that talks about Market Mapper
Late yesterday I learned from Twitter that Whitney Houston died.
99% of the Whitney Houston Tweets were exactly, “RIP Whitney Houston.” Okay… but how did she move you? Do you remember a special dance with that one girl while she was singing? Was her voice so beautiful that it made you tear up? It was for me. Originality is there, but buried on Twitter. I would have enjoyed others insights on Whitney, to feel camaraderie in a shared loss. If it existed on Twitter, it was obfuscated behind all the drone “RIP Whitney Houston” tweets. So instead I played some Whitney songs and told my children who the woman with the beautiful voice was.
Twitter is big data.
“Big data” is making the news. The concept has crept from the back pages of technical publications into the mainstream. It’s a new topic, so the reporters have commandeered it. It’s becoming popular, and that’s too bad. Media feeding frenzies perpetuate the peripheral definition; articles get copied over and over again, and people stop thinking.
With their IPO in the news, Facebook has become the poster child for big data. So what is it? What is big data? Simply put, massive amounts of information about millions, and eventually, billions of people. Big data is making the news because of fear – fear of the possibilities of abuse. It sells newspapers, gets clicks, and page views which means we will be hearing a lot about big data. Scare people and make money.
Facebook is big data.
Google is changing its privacy policy. Another media feeding frenzy. If you have a Gmail account, Google+, music, shopping, etc. All the privacy policies are melding into one. I like the idea and I have to admit, I don’t understand the problems people are having. If you use 5 or 10 different Google services, are you really going to read many different user agreements? I don’t know anyone who actually does. I would prefer to have one policy that covers them all. Google gives these services away, if you don’t like that one, single policy – stop using the service. The chances of people being informed about Google’s policies will increase if they have a single policy. It’s a good thing. Stop the bitching.
Google is big data.
Another bit in the news. The Seattle Times reports a top porn site, Brazzers, was hacked. From the article, and other news about regarding it, usernames, passwords and real names were hacked. The data is making its way across the Internet on file sharing sites.
Internet user databases are big data.
In my vision of the world, big data is in its infancy. Don’t freak out for at least 10 years.
Why now? Why is big data coming into mainstream now? It has been around for many years. Large data providers like Experian, Axiom, and D&B have been collecting data for a long time. What is different now? To ask “why now,” you must understand the continuum of getting at big data.
11 big Data Prerequisites
The data must be there – this is the most exciting tipping point. In being the CEO of a data-mining software company, I’m still dumbfounded when users expect to get information off the web…that is not there. It must actually exist.
You must be able to flag it – you can’t store everything and must make choices. What is important? When does it happen? Example: News release with subject: Nanotechnology
You must be able to find it – in the absence of a real-time data stream, you must able to search though data to find a “flag” of what you are looking for.
You must be able to parse it – this is the analysis of relevant grammatical constituents, identifying the parts of what you need, from within potential noise. Example: parsing out the name of an inventor from within an article on nanotechnology
You must be able to extract it – Not the same as parsing. What if the data is in a PDF file or HTML web page? In many cases, extraction is about access. Is the data I am looking for across 5 sub-links of a single web page? Extraction as it relates to the Internet also encapsulates web crawling.
You must be able to process it – This takes CPU cycles. Bigger problems need bigger computers.
You must normalize it – If you have multiple pieces of data on “The Container Company”, “Container Company, The”, “The Container Co”, etc, how do you merge that data? You must normalize like entities to a standard “canonical form”. With out it, we’ve got the Data Tower of Babel.
You must be able to store it – Big data takes up disk space.
You must be able to index it – If you ever want to find it after you store it, the data needs to be indexed. This also means more disk space.
You must be able to analyze it – big data needs big (or many distributed) CPU’s to crunch the numbers and garner order from the chaos.
There must be a payoff – Putting together big data is expensive. Without a end goal in mind, it is expensive to collect. Google & Facebook collect, process, index & store data for profit.
So what is my vision of “big data”? What is being talked about in the media is very short sighted. I think I know where big data is going. I’m basing my vision on my prerequisites.
Big Data Thoughts
1: Information is growing beyond the ability of any single source to store and index everything. Therefore, big data can never be “all data.” Facebook and Google cannot store everything. Therefore choices must be made. Google already does it; indexing what they deem relevant.
2: The amount of data about people on Facebook is paltry…compared to the maximum possibilities. Yes, in aggregate, it is the largest set of minimal data. Think for a second about your day. What would it take to record your entire life in HD, from 7 different angles. This future data stream would include everything you heard, read, and generally interacted with.
3: Mass, personal data recording is on the horizon. The first phase is already starting. The only limit is reasonable storage. The term is called “LifeLogging.” There are devices that you can wear and it will take a picture every 30 seconds. High quality LifeLogging technology will be critical in the future. Every 30 seconds is 1/900th of video (30 frames per second). If the Lifelogging device is just the conduit vs. the storage medium, the lifelog could be stored on your home PC. With h.264 video compression and 5.5 hours of 1080p video can be stored on a 32GB thumb drive. That means a single 1TB (terabyte) drive can hold 176 hours of hi definition video (7.3 days of video). It would be expensive today to buy 52 X 1TB drives to store a year of your life. It seems crazy… right? Not when you are a historian. In 1992, the average hard drive was around 1GB – 1000 times less than today.
Some ideas to reduce the storage size of LifeLogging:
-Go vector. If you have an avatar created of you, a vectorized version of you could be stored. This type of compression does not exist, but it will. LifeLogging in bitmap video is like a tape deck. Vectorizing video with the lifelogee as the center of the story would save 1000X the storage. It is like the hard drive compared to tape storage. In addition, storing data in this way could be accessed very quickly. Bottom line: with the right *Software* real LifeLogging could be done today. I should save this for another in-depth blog. I’ve spent many nights thinking about how it all could be done. I’ve got to stop watching Sci- Fi before bed. Lawn Mower Man
4: Assume that we are in the 2020′s. Based on Moore’s Law, and several others, A LifeLogging device will be able to be worn around your neck, and record your life in HD. They’ll probably be the price of premium iPad. At that level, LifeLogging is ubiquitous.
5. What did I eat today? What about over the past week, month, or year? Just because that information, is recorded, as video (me munching Apple), does not mean that it can be analyzed and recognized as Donato-eats-apple. Where did you buy that Apple? Can the date of the purchase be cross referenced with the date that you bought it at the grocery store?
New industries
Software that analyzes and makes inferences from LifeStreaming (the will be a multi-billion dollar industry. (Donato ate apple, Donato started car, Donato got phone call, Donato was watching the movie Contact). I would expect that each major type of world interaction would be handled by a different app or algorithm.
Software that compiles inferences, builds statistics and performs what-ifs on mass LifeStream data will be multi-billion dollar industry. (23% of people that ate apples 4x per month, where the apples came from Chile, and most likely were treated with chemical X, developed cancer by age 55). These are the types of discoveries we will be able to make that are currently only made by virtue of a happy accident. (I made up that example…but do eat organic apples).
Example: compiling a list of the junk (postal) mail letters that I throw out without opening. That is good data. What is the one that I opened?
Software that manages the rights, payments, connectivity and privacy between life streams will be a multi-billion dollar industry. So if that apple from Chile used some real nasty pesticides – like a carcinogen? Could that supplier of that apple to the store be tracked? Do you want to know this? What if your wife bought it… and it is not part of your personal data stream? Do you and you wife have a LifeStream sharing agreement?
One person, eating one Apple does not a trend make. Multiply that by 50 million people over 5 years. This is not science fiction. This is simply faster computers, more memory, and analysis software. It’s a lot of Apples. Do I want to share, if it was anonymous, my eating habits and cross reference it with my health…maybe.
I expect that companies will pop up, each with a different set of analysis technology for different niches. It will probably evolve into an AppStore model. One company looks at how you interact with media, what you watch, listen to, theaters attended. Another knows what you eat. You can choose which feeds to share with the greater LifeStream and take part in a greater community.
By the way, none of this LifeStreaming will be on Facebook, or Google+. No one would trust them. In addition, it would be prohibitively expensive to centrally transmit, store and analyze it. Hmmm, maybe Facebook could be the trend builder? It is well positioned for it. Can you imagine it?
Donato ate an Apple
Donato threw core in garbage
Donato did not recycle V8 can
Donato is driving 15 miles over the speed limit
This is the first time in a few years that I thought of a way for Facebook to survive long term. In this Facebook, you would never log in to look at what people are doing, you would log in to see that latest trend and how it affected you.
I just hope it does not make it to twitter and get retweeted by the “RIP Whitney Houston” drones. Once analysis agents can understand (and broadcast) our individual actions, Twitter has no reason to exist.
Big Data equals big money.
If it is possible, and someone can profit, it will be collected.